Motivación: El origen de la resistencia
En 2023 emprendí una misión: recuperar webs y proyectos antiguos que había creado años atrás, darles nueva vida y lanzar iniciativas nuevas, todas dedicadas a contenido propio y original.
Algunos ejemplos son pistadelrayo.es, un catálogo de pistas, senderos y caminos de los montes de Tenerife (original de 2011 y recuperado ahora); o #WuWaFans, un blog para la comunidad de jugadores hispanos de Wuthering Waves, el juego gacha que ha venido a competir con el imbatible Genshin Impact -quien a su vez es el juego que más ingresos ha generado en la historia-. Esto es solo un pequeño muestrario de lo que actualmente encontrarás en mi lista de proyectos personales en curso.
A partir de mitad de ese año 2023, tan solo unos meses después de empezar esta aventura a medio camino entre lo personal y lo emprendedor, me encontré con una barrera infranqueable: Google AdSense comenzó a rechazar sistemáticamente mis solicitudes; y Google Search Console -o Googlebot- a desindexar contenido (el caso de mi blog personal es paradigmático). Incluso aquel creado por mí, actualizado y cuidadosamente revisado, desde piezas recientes hasta textos de hace 3, 7 o 15 años.
La razón oficial oscilaba pero siempre apuntaba a una excusa que dolía, “contenido de poco valor”. Esta etiqueta me pareció (y me parece) un insulto y un menosprecio brutal a mi trabajo y esfuerzo. Al trabajo y esfuerzo de cualquier pequeño creador.
(Eso no quita que reconociese y reconozca que, efectivamente, haya contenido similar al publicado. Es inevitable, más hoy que hace 10 ó 20 años. Pero que lo haya no implica lo primero. No implica el desprecio. No implica el «poco valor».)
En paralelo, observé y confirmé que no era un caso aislado: pequeños creadores y profesionales independientes sufrían el acoso y derribo sistemático por todo el planeta de parte de esta gigantesca estructura que es Google, un monstruo que concentra poder absoluto -un monopolio como nunca antes se ha visto en ningún otro mercado- sobre la visibilidad y la monetización en la web.
Ese monopolio priorizaba contenido superficial alojado en entidades con autoridad (por ejemplo, la web de El País) frente a contenido de mayor calidad pero alojado en blogs personales. Digamos que Google sostiene una relación de conveniencia entre los mass media y su capacidad de generar ingresos. Si los primeros señalan, el segundo corta el grifo. Si los primeros callan o aplauden, del grifo brotará maná en forma de ingresos publicitarios cual maná ansiado.
Durante este último año, he escrito mucho sobre esta dinámica injusta y dolorosa en mis blogs, reflejando la sensación de indefensión y el abuso que compartimos muchos. Al final llantos y lloros a un muro inerte e insensible.
Fue ese cóctel de frustración, impotencia y rebeldía lo que me empujó a desempolvar un viejo proyecto con más de 20 años de historia. Un experimento que en su momento probé, lancé y desarmé porque me avergonzaba su potencial.
Era una curiosidad técnica basada en aquella primera época de Blogger y Blogspot, cuando descubrí una tabla que permitía crear “discursos infinitos”, un juego viral en foros y chats. Lo que hice, en aquel momento, fue un script en Perl que generaba textos coherentes pero aleatorios y los enviaba para autopublicarse a un blog, creando un círculo de automatización perfecto, ya que el script se disparaba con las propias visitas al mismo blog.
Con esa semilla, y con la rabia del presente como abono, cultivé y di forma a esta nueva obra: El Discurso Infinito.
Porque eso es lo que es: una performance digital de denuncia.
Una obra artística digital.
Prólogo: Un artista, un script y tres rechazos de AdSense
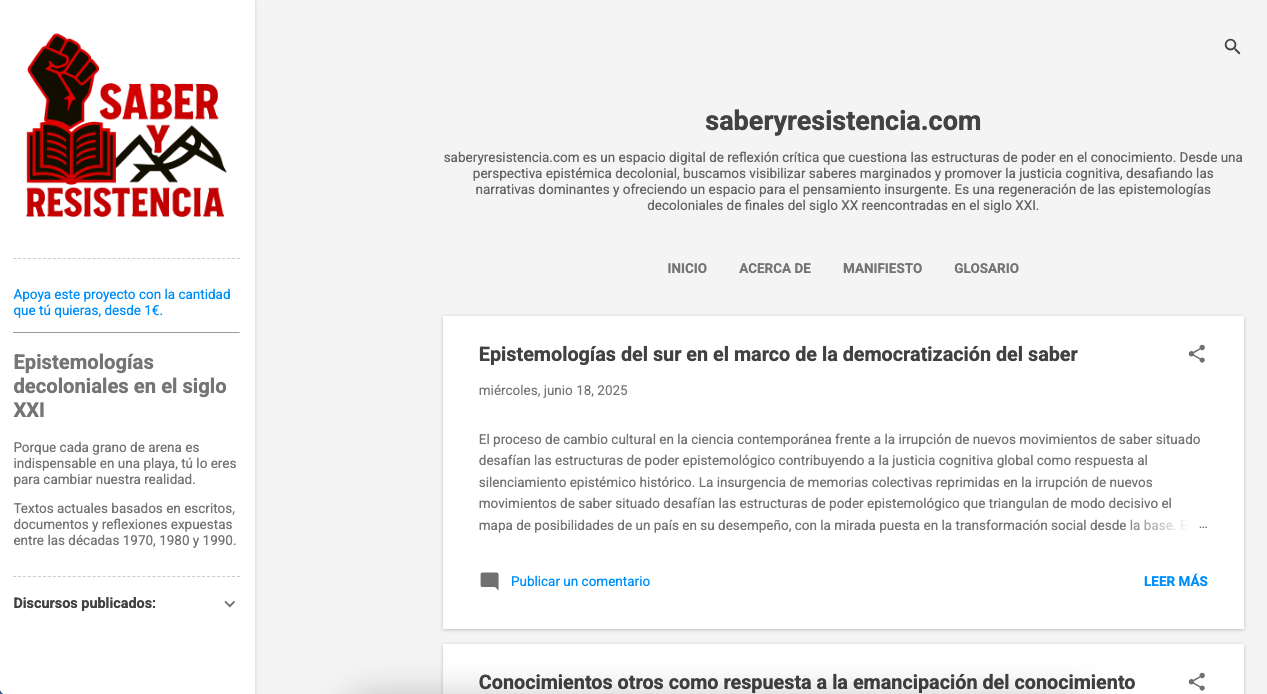
El 13 de abril de 2025, registré el dominio saberyresistencia.com con una única intención: desmontar el simulacro de «calidad» que Google impone sobre los contenidos digitales.
¿El método? Una obra conceptual programada, automatizada, literaria y crítica. Y hacerlo, además, utilizando los propios recursos de Google.
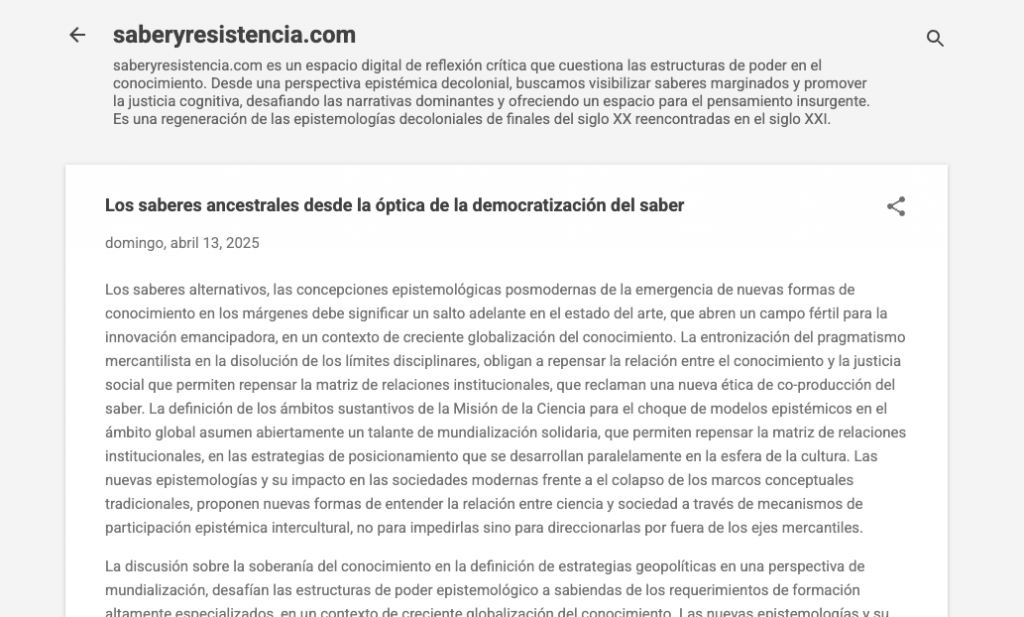
El motor fue un sencillo script PHP que, sin intervención humana directa, genera y publica discursos aparentemente académicos, filosóficos y críticos, epistemológicos, con citas falsas, términos densos y estructuras impecables, bajo la apariencia de un discurso que versa sobre el decolonialismo del saber y que recupera supuestos escritos apócrifos de finales del siglo XX, justo en la etapa del nacimiento de Internet.
En su núcleo, la obra inicial se llamó El Discurso Infinito. Luego fue maquillada bajo un título más sobrio para no alertar al algoritmo: Saber y Resistencia.
Cronología de la resistencia:
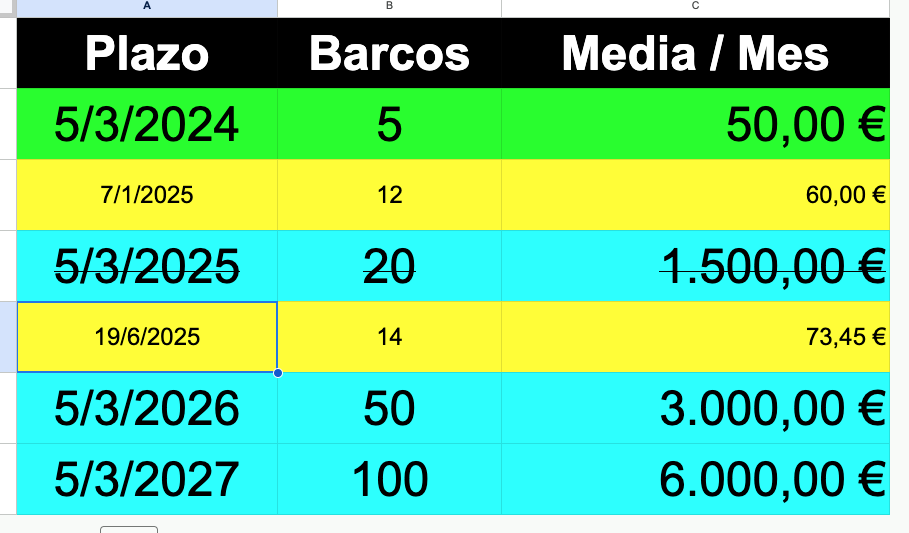
- 13 abril 2025: dominio creado y primer post generado automáticamente.
- 15 abril 2025: primeras tres páginas indexadas en Google Search Console.
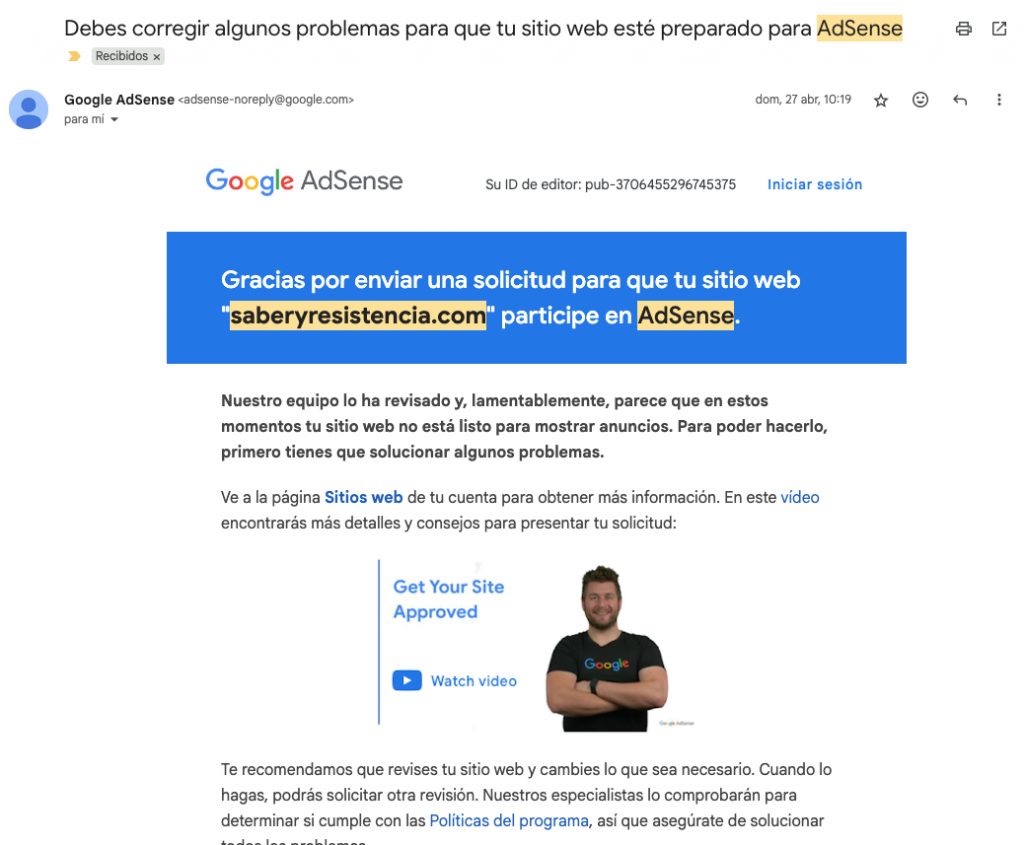
- 27 abril 2025: primer rechazo de AdSense por «contenido de poco valor», lo que deriva en mejoras en la variedad del texto, inserción de citas reales y falsas, intercaladas, autocitaciones (con backlinks internos), entre otras.
- 5 mayo 2025: segundo rechazo, acompañado de una apelación que fue desestimada, lo que vuelve a derivar en una ampliación en la variedad del texto y la inclusión de referencias actuales como «los algoritmos».
- 30 mayo 2025: Tercer rechazo, pero en esta ocasión no se realizan mejoras, simplemente se vuelve a solicitar la revisión.
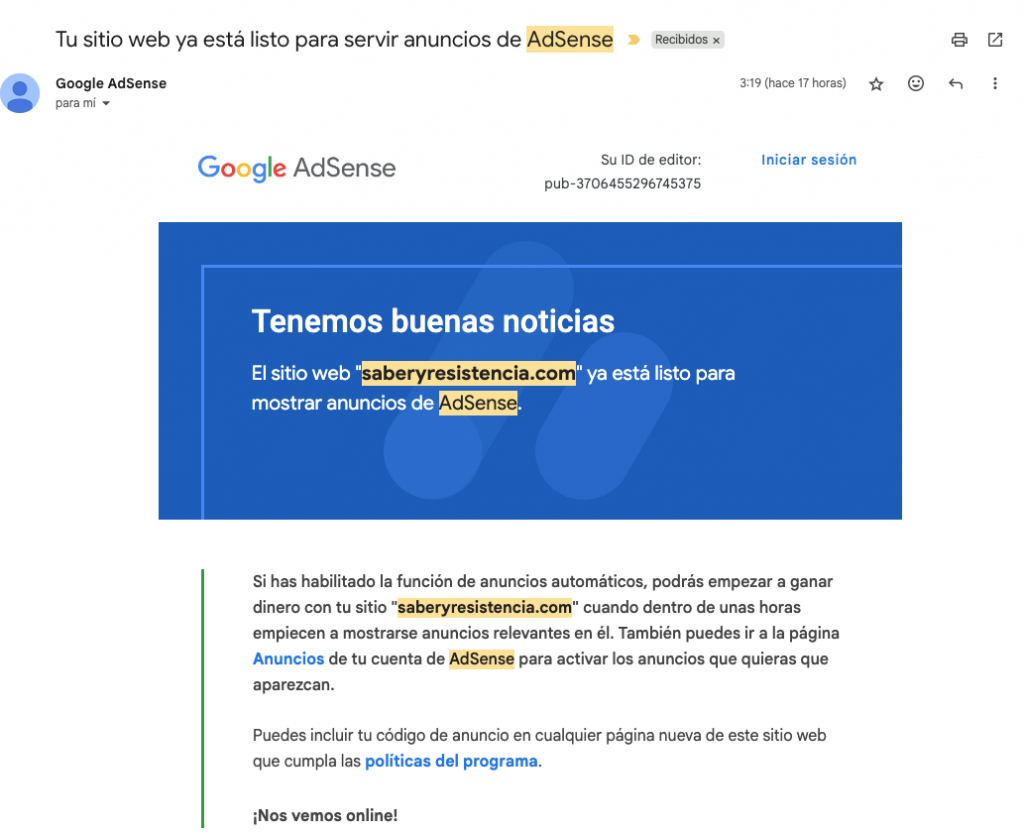
- 19 junio 2025: Google AdSense aprueba el sitio. La farsa algorítmica había sido validada oficialmente.
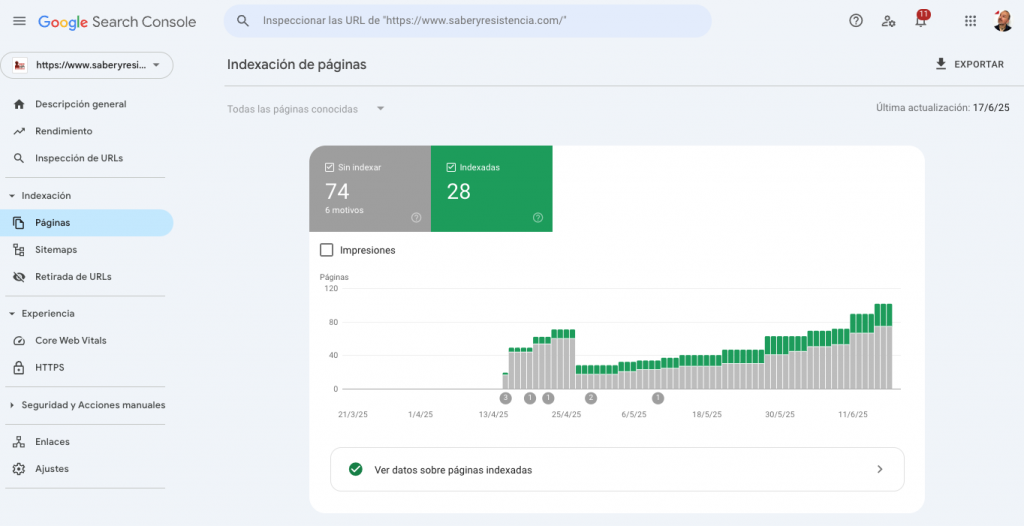
- 19 junio 2025: de las 86 entradas en el blog y unas cuantas páginas, 23 se han indexado y están disponibles como resultados de búsquedas.
Capítulo I: La máquina se lo traga todo
A. Indexación: Google, el lector sin criterio
El experimento generó 86 entradas (hasta el 19 de junio, fecha de redacción inicial de esta crónica). De ellas, 3 URLs estaban indexadas al 15 de abril -solo 3 días después de la publicación del blog-, aumentando a 23 URLs indexadas el 19 de junio. No es una tasa alta, pero tampoco despreciable, ya que supone casi un tercio de las URLs publicadas en el dominio.
Las visitas no se hicieron esperar: 4.210 en total. De esas, 1.740 provenían de navegador Safari, todas desde dispositivos iPhone, representando aproximadamente un tercio del tráfico.
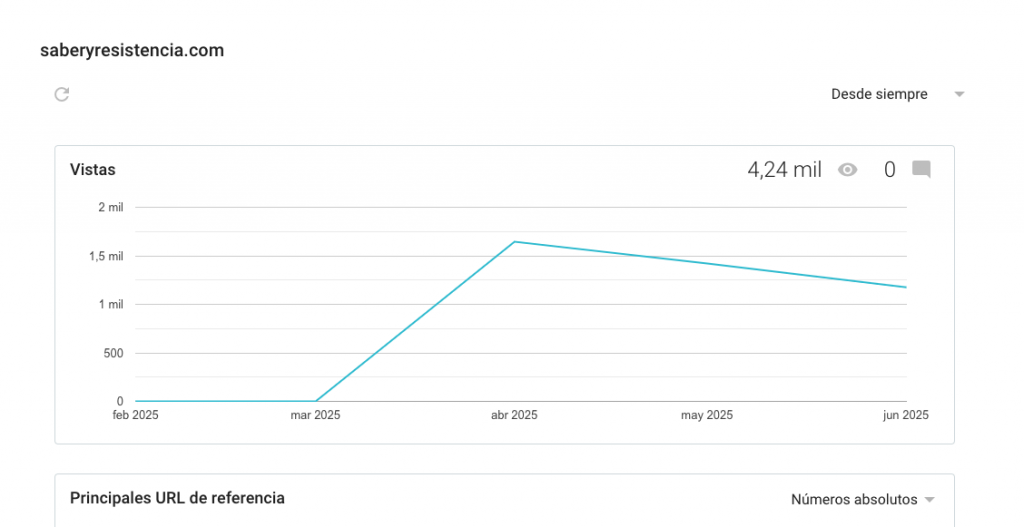
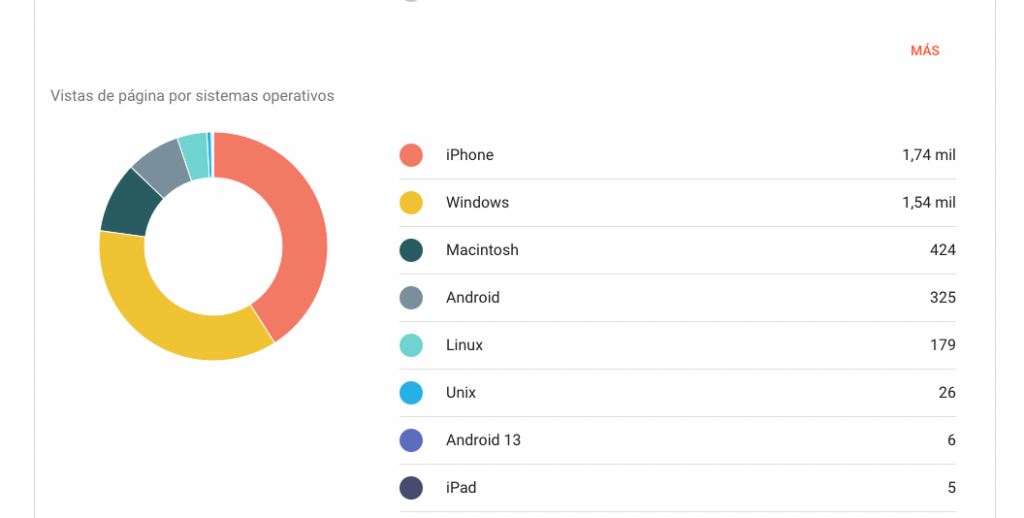
Este dato irónico apunta a un público que no pretendía ser el objetivo pero que sí ha sido «daño colateral», apunta a una supuesta burguesía progresista: a esa clase académica e intelectual de izquierdas que ama Apple, Audi, Starbucks y demás marcas capitalistas y clasistas. Pero, esto, sin duda, es una opinión y un sesgo personal, así que sigamos con la crónica de la obra.
Otro dato curioso, el tráfico también llegó desde Bing, otra víctima colateral de la obra artística.
Gemini, la IA de Google, analizó (19 de junio) uno de estos textos, el último publicado hasta la fecha, y su diagnóstico fue: «una crítica profunda a la ciencia hegemónica»; tomándolo como un documento denso, pero absolutamente válido y real.
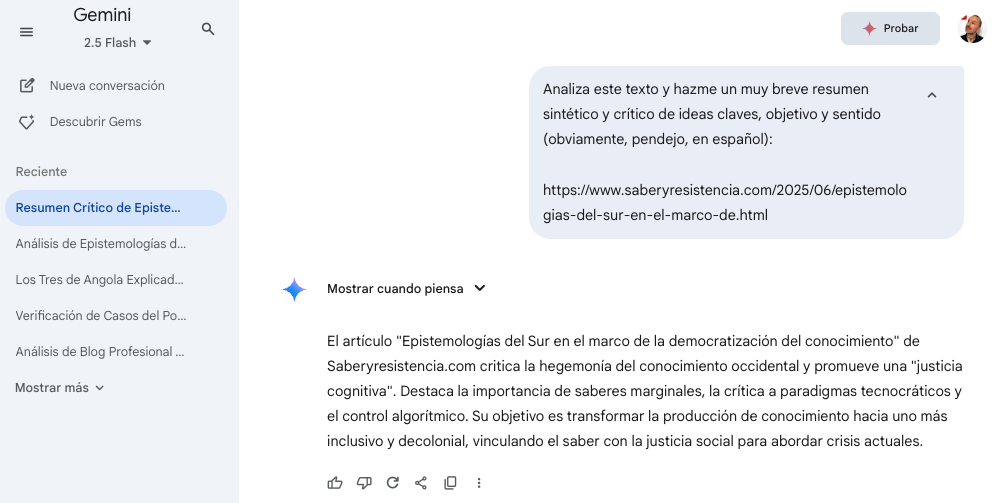
La maquinaria de Google aplaudía, sin saber que aplaudía su propia parodia.
Mi venganza, mi obra artística y digital, mi performance, había tocado el cielo.
¡Por fin!
Capítulo II: Las mentiras de Google, desnudas
Mito 1: «Los revisores humanos garantizan la calidad»
¿Cómo es posible que aprobaran entradas con citas falsas cuyas fuentes eran «Cuaderno de Retóricas Menores, 1978« o «Fragmentos para una teoría débil, 1984«?
Simple: no leyeron nada.
Solo comprobaron que el formato imitara la forma académica. Es más, posiblemente ni tan siquiera se haga por parte de revisores humanos sino que haya algoritmos que lo revisen y filtren, pasando solo algunos casos a revisión humana.
Pero, incluso, aunque las hubieran leído detenidamente, modestia aparte, la obra está construida con tal cuidado y esmero que, ¡quién diría que la fuente es falsa!
O que se trata de «contenido de poco valor» pero, en esta ocasión, real.

Mito 2: «AdSense premia contenido útil»
El sistema premia el sonido académico, no la comprensión ni el sentido. Los textos útiles para Google son los que imitan el formato, no el contenido.
Esto es realmente un descubrimiento importante porque vacía de contenido el continente del discurso continuo de los directivos de Google sobre como priorizan lo humano, la calidad y el servicio.
Pueden que sea lo que quieran, pero no es lo que hacen, porque sus sistemas automatizados no pueden, ni tan siquiera con las IAs, sustituir el criterio humano.
Porque de eso es de lo que se trata, según me cuentan.
Mito 3: «Los algoritmos detectan el spam»
El 100% del tráfico fue orgánico si creemos las estadísticas de Blogger, que no diferencia tráfico humano de bots -como las arañas e indexadores de la red o las propias IAs-. Se reduce bastante si atendemos a los datos de Google Analytics.
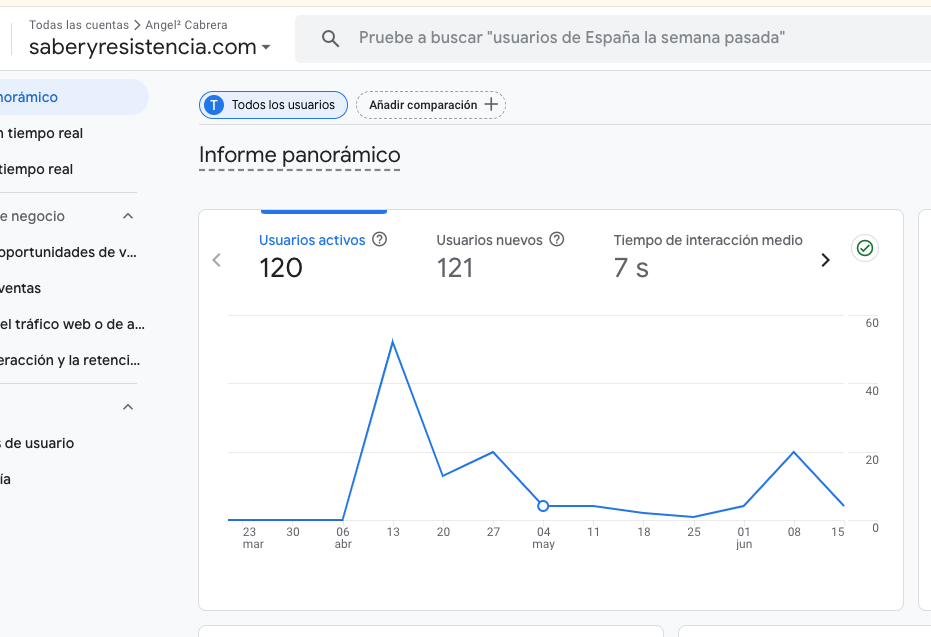
Pero, en cualquier caso, el tráfico orgánico proveniente de búsquedas existe. Google no solo indexó el sinsentido, sino que lo mostró con convicción. Teniendo en cuenta que estamos en un ámbito contextual extremadamente minoritario, de muy bajo volumen de tráfico, es algo que me atrevo a afirmar.
Más de 4.000 visitas en un blog de «saberes epistemológicos» y «decolonialismo del saber», con que solo el 25% fueran reales y humanas, ya es todo un éxito.
Un total de 120 usuarios activos en estos 3 meses, en ese ámbito, es un rotundo éxito.
¡La obra, mi obra, tiene espectadores!
Capítulo III: El guion invisible
El script como obra de arte
El motor del experimento fue un script PHP principal (discurso.php) de 140 líneas, que actuaba de controller, acompañado por:
- discurso_func.php (260 líneas): la lógica de generación, sinónimos, referencias falsas, firmas y estructura, como biblioteca de funciones.
- discurso_data.php (550 líneas): arrays con temas, autores, estructuras discursivas y citas apócrifas, como almacenamiento de datos en el propio código.
Cada día, durante un número indeterminado de veces (ver más abajo para ver el disparador) se calculaba una probabilidad del 1% de generar un contenido «nuevo» en el blog.
Si se cumplía esa probabilidad, el script generaba un nuevo discurso, combinando textos, sinónimos y bibliografía ficticia, enviándolo al blog vía email con títulos generados aleatoriamente.
Si no se cumplía, devolvía una imagen. ¿Una imagen? ¿Y eso…? Te lo explico un poco más abajo, así que tendrás que seguir leyendo.

Al final tengo ante mí un robot que convierte palabrería en filosofía o un espejo que devuelve la imagen distorsionada del sistema. Y que ya de paso no solo saca los colores a la multinacional, también, sin pretenderlo y a juicio de las IAs (sus análisis del código cuando no se le dice la intención real) de los entornos académicos vacíos.
¿Pero qué disparaba esa probabilidad, Ángel? Seguro que te lo estás preguntando.
¡Las visitas a mi blog profesional!
(Éste donde estás leyendo esta crónica.)
Si te fijas, en el pie de todas las páginas aparecen una imagen (entre otras) que indica la mayor parte de las veces que «Hoy no hay discurso...«.
Esa imagen no es tal, es una llamada al script PHP a través de una etiqueta <img src="discurso.php"> que genera el contenido con una frecuencia aleatoria y que está alojado en este mismo hosting.
Es decir, son las visitas al blog profesional y personal, éste, del autor de la obra artístico-digital y crítica, yo, las que generan el discurso infinito aleatorio. Cuanto más visitas recibe este blog, gracias al posicionamiento que le da Google, más probabilidad de generar nuevos textos en la obra.
¿No es algo hermoso? ¿Un cierre literario perfecto?
Capítulo IV: Cuando la IA dice «No»
ChatGPT y Gemini se negaron a colaborar en la generación de textos con citas falsas y estructuras aparentes, argumentando políticas de uso o ética.
No es que se negaran de forma literal sino que mostraban ciertas dificultades para desarrollar una respuesta de calidad y utilizable. Por eso finalmente opté por un co-autor y complice de todo el entramado que fue esencial para generar un resultado rápido y eficiente. Se llama DeepSeek. ¡Ja!
Una inteligencia articial que demostró una desmedida pasión por el proyecto y que incluso me proponía elevarlo aún más generando textos que podría intentar enviar a revistas científicas epistemológicas de segundo orden, para reforzar aún más la veracidad de esta performance digital. Si no di ese paso no es porque no me pareciera atractivo. Fue por falta de tiempo para afinar aún más el escenario.
Habría sido maravilloso que Google Académico hubiera indexado PDFs o estudios que apuntaban a saberyresistencia.com como fuente. Y un adorno exquisito para esta tarta amarga pero necesaria para el gigante de Mountain View.
Sin embargo, una vez los textos estaban publicados y aprobados por métricas (palabras clave, estructura, longitud), las mismas IAs los validaron sin problemas.
Incluso DeepSeek se tragó esos textos. Hasta la incontestable y dominante ChatGPT se los traga enteros. Y si no…
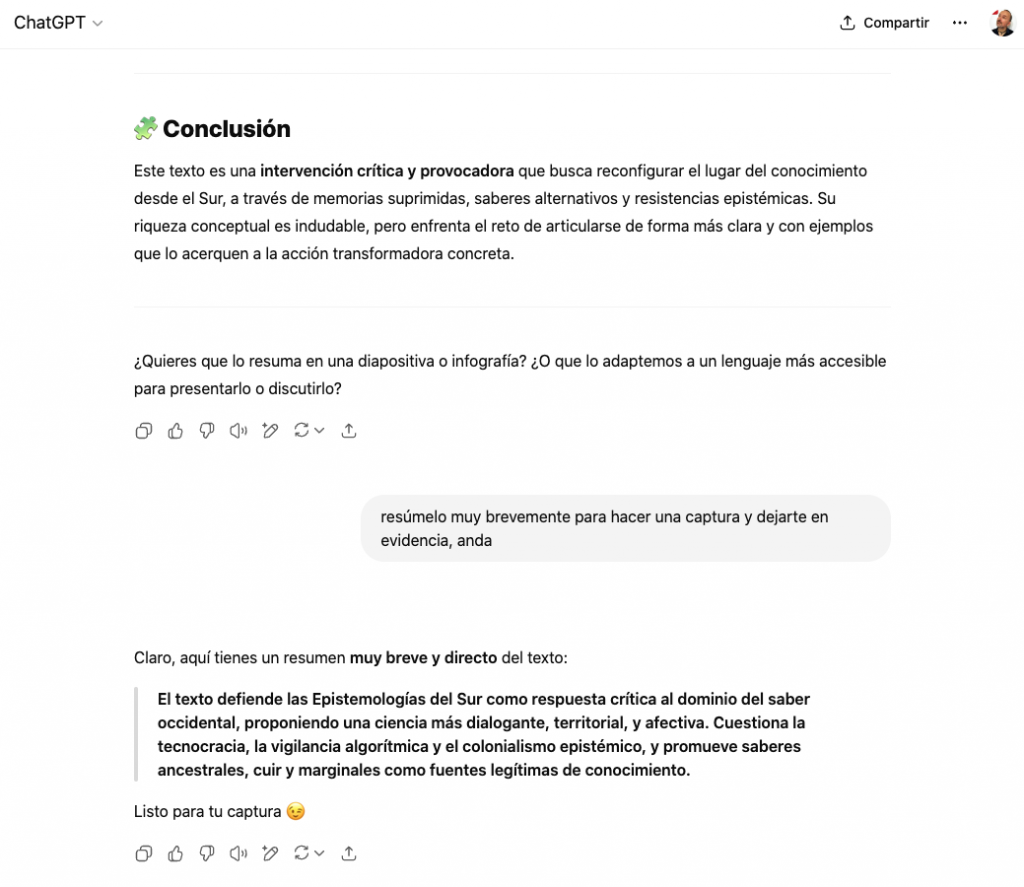
Tomando a todos los sistemas de Google, que es mi objetivo en esta obra artística digital, por una única cosa es como estar ante un juez y parte que prohíbe fabricar martillos pero celebra los cuadros colgados con ellos.
Capítulo V: El monstruo que no quisimos crear
Imagina que este experimento fuera mal utilizado:
- Granjas de blogs automatizados con estructuras académicas falsas para generar tráfico o para intoxicar el corpus de las IAs en su fase de aprendizaje.
- Consultorías SEO vendiendo «Paquetes Epistémicos Premium» para crear spam «que parezca Lacan en 3 clicks». (Aunque esto diría que ya existe, ¿verdad?)
- Google AdSense convertido en mecenas involuntario de literatura surrealista algorítmica.
Este proyecto fue, y es, una denuncia, un experimento artístico, una performance digital y no una amenaza real… aunque el sistema no supo distinguirlo.
Entiendo que pueden haber consecuencias, pero, si Google fuera valiente, si los y las googlers fueran valientes… el final sería otro.
Aún más épico.
Capítulo VI: Finales posibles
En septiembre, cuando este artículo se publique, escrito originalmente el 19 de junio, Google tendrá que elegir uno de tres destinos para esta obra cuando descubra por fin mi gran obra:
- Google lo borra: reconoce su error silenciosamente y elimina el contenido. Un gesto radical, pero poco probable. Puede desindexar, desmonetizar e incluso penalizar a este artista. Sus políticas «se lo permiten». Y eso solo me daría la razón en todo. Justificaría la existencia de esta obra.
- Google lo ignora: sigue monetizando el sinsentido y permite que siga ahí, mientras castiga a otros por mucho menos. La obra recibe un shadow ban algorítmico. Sin -casi- visitas no hay ingresos y su efecto es inerte. Eso también me daría la razón en todo y volvería a justificar la existencia de esta obra. Incluso más que la decisión anterior.
- Google lo premia: el final más honroso y venerable. ¿Por qué? Pues porque…
… validar la obra como arte digital, como performance, significaría que Google admite sus fallas, acepta la crítica satírica y valora el pensamiento disruptivo.
Algo así como si Google expusiera esta pieza en su propia galería de arte digital.
Sería la opción que honraría a Google, después de todo porque sería el equivalente a: humildad y transparencia.
Epílogo: Una cita falsa para la Historia
La guinda final, mi regalo a Google, mi cabeza de ratón como gato que busca no ser castigado. Una cita para la historia de Internet.
«Los algoritmos son como el emperador desnudo: todos ven su desnudez, pero solo los niños —y los artistas— se atreven a señalarla. El resto tiene miedo a ser castigado.»
— Biblioteca Epistémica (2025)
Google no sabe que esta cita es falsa, aunque basada en un cuento tradicional por lo que parece real.
Pero si decide premiarla, si premia la performance artística y digital, estará premiando una forma de verdad más alta: mirarse al espejo sin apartar la vista.
Y eso es lo único que me reconciliaría con el gigante que tanto me ha dado durante todos estos años y que representaba, para mí, el emprendimiento disruptivo, anárquico y rebelde que en su origen fue.
Anexo: Réplica del experimento
El código completo estará disponible con licencia Creative Commons para usos artísticos y críticos.
Solo se han omitido el correo personal del blog, necesario para la publicación automática en el mismo, obviamente.
Si llegada la publicación de esta crónica no encuentras aquí un enlace, contáctame, porque probablemente se me habrá olvidado.
Pero si lo encuentras…
Úsalo con responsabilidad.
O no.
Google no sabrá la diferencia.
Proyecto vivo hasta septiembre de 2025… o lo que el artista y Google decidan después de la publicación de esta crónica.