La verdad, me apetece escribir sobre las cosas chorras en las que me fijo y de las que me gusta escribir, aunque no generan tráfico. Sí.
Pero.
Debería escribir sobre mi formación y acreditación como científico de datos (¡toma etiquetazo!) con IBM y gracias a FUNDAE.
Y ahora que he terminado el curso «2 de 12» sobre herramientas en la ciencia de los datos que menos que hacer un repaso generalizado. (Aunque la verdad es que casi me pilla el toro con el de metodología en la ciencia de los datos casi a la mitad.)
Un científico de datos, ya lo he contado, es alguien que trabaja con datos para obtener un aprendizaje para una organización. Busca, extrae, procesa, analiza y aprende, generando un resultado que es evaluado y que sirve para retroalimentar la maquinaria. Explicado con mis propias palabras pero que no distan mucho de lo que se puede leer por ahí.
Para él, o ella, las TICs son una poderosa herramienta que le permite automatizar y acelerar ese proceso. Nada que ver a como se hacía con ábacos. ¡Jeje!
En esas herramientas tenemos:
- Gestión de datos: almacenamiento, gestión y recuperación de datos, estructurados o no.
- Integración y transformación: agilizar la extracción, la transformación y la preparación de datos y automatizar las tareas de procesamiento de datos, lo que ya no solo incluye SQL sino también programación, servidores varios y otras delicatessen.
- Visualización de datos: es decir, entender o comprender los datos que tenemos entre manos y ser capaces de hacernos preguntas (plantear hipótesis), lo que incluye desde hacer un gráfico en Excel hasta manejar ggplot2 con Python.
- Modelización: es decir, aprender, o mejor aún, permitir a una máquina poder desarrollar un aprendizaje que posteriormente sirva para predecir, clasificar y/o explicar lo que sucede (y más).
En la práctica esto le lleva a sentarse delante de:
- Gestores de versiones: y aquí nos referimos básicamente a repositorios como GitHub hasta usar editores como VScode donde no solo pueden controlar y gestionar el desarrollo colaborativo sino también datos y otro tipo de ítems útiles para cada proyecto.
- Gestores de bases de datos: lo que nos lleva a dominar, de entrada, muy bien, el SQL, pero también a usar y gestionar servidores para tal fin, no limitándose a datos estructurados sino también (y más actualmente con los macrodatos o big data) los servidores NoSQL.
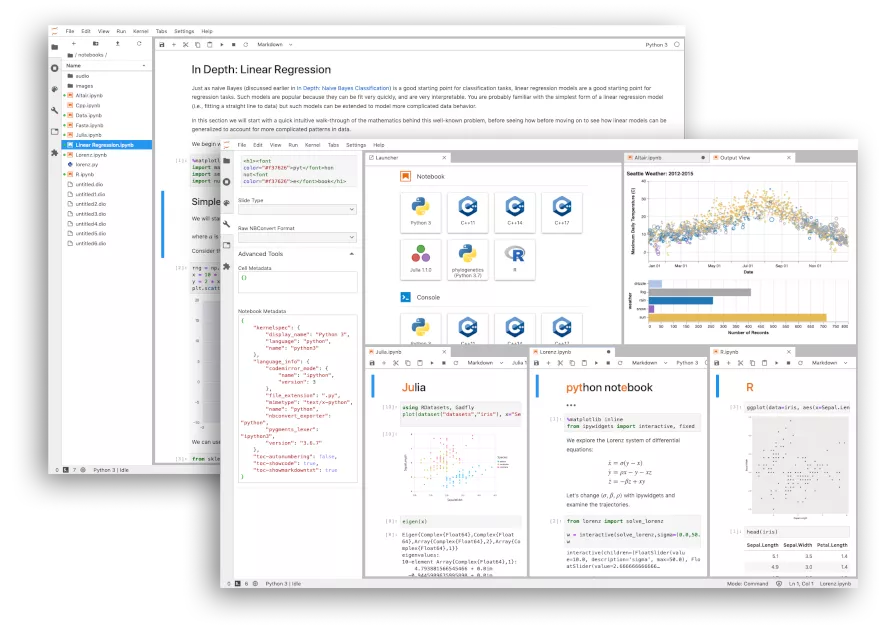
- Frameworks: o entornos de desarrollo que van desde editores de código como VScode hasta interfaces más complejas, añadiendo aquí los entornos como Watson Studio de IBM útiles para, entre otras cosas, trastear con los cuadernos Jupyter o el propio Jupyter Notebooks que es opensource y sin cuotas mensuales… cof, cof, cof… con sus múltiples kernels que te permiten utilizar múltiples lenguajes de programación o, uno de los más usados en este ámbito, RStudio.
- Entornos de ejecución y producción: es decir, testar y poner en marcha sus resultados.
Claro, cuando te dicen esto, lo primero que piensas es… ¡un ingeniero informático!
Pero no.
¿Pues un estadista?
Pues tampoco.
¿Un administrador de servidores?
Que no, que no.
Un líder que exponga unos resultados e impulse un cambio organizacional.
Tsk… no.
¿Todo eso junto?
Casi que sí.
Y en este segundo curso, ¡por fin!, hemos empezado a trastear y cacharrear con Jupyter y con Python.
Quedan 10 más.